


 币种收益
币种收益
 矿机收益
矿机收益
 显卡收益
显卡收益
 收益计算
收益计算
 矿池信息
矿池信息
IPFS文件长什么样?我们该如何构建?
2020-09-27 08:32:02
来源:IPFS时空云 作者:IPFS时空云 阅读:11710

IPFS如何帮助区块链存储数据?

IPFS的核心是一个分布式系统,用于存储和访问文件,网站,应用程序和数据。它与传输层无关,这意味着它可以在各种传输层上进行通信,包括传输控制协议(TCP),uTP,UDT,QUIC,TOR甚至是蓝牙。
相比于HTTP,IPFS的传输速度之所以更快,在于IPFS是通过哈希标识的方式查找文件的,当你拥有哈希后,你会询问并连接到的网络“谁拥有此内容(哈希)”。然后连接到相应的节点并下载,也就是说,这能形成点对点覆盖,从而实现非常快速并且广泛和即可使用的路由。


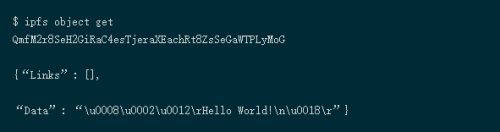
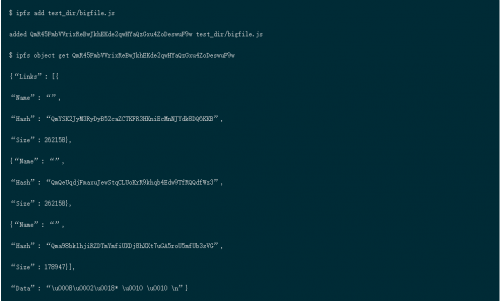
数据 :大小小于256 kB的非结构化二进制数据的容量
链接 :可以链接到其他IPFS节点
名称:链接的名称
哈希:链接IPFS对象的哈希
大小:链接的IPFS节点的累积大小,包括跟随其链接的位置






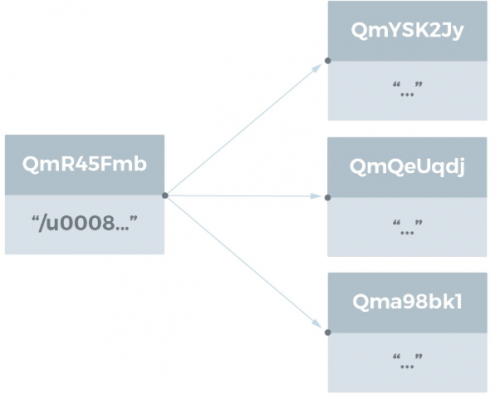
 目录结构
目录结构
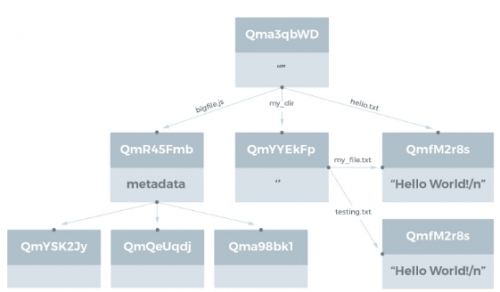


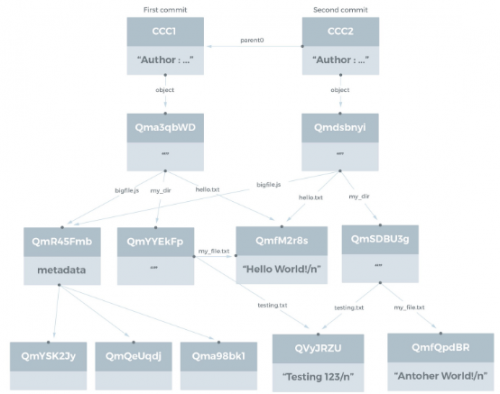

交易对象清单
到上一个块的链接
状态树/数据库的哈希
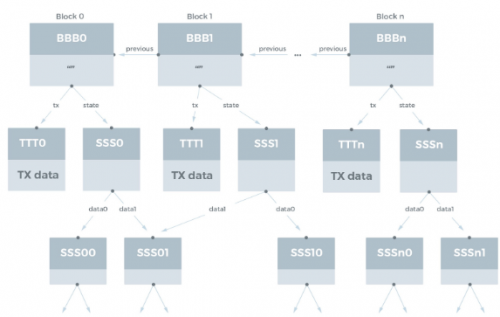
如果在IPFS中已经表示了具有相关状态数据库的区块链,那么将哈希存储在区块链上和将数据存储在区块链上之间的区别就变得模糊了,因为无论如何所有内容都存储在IPFS中,并且仅区块的哈希需要状态数据库的哈希值。在这种情况下,如果有人在区块链中存储了IPFS链接,我们可以无缝地跟随该链接来访问数据,就好像数据存储在区块链本身中一样。
声明:此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。本网站所提供的信息,只供参考之用。
- 相关阅读
-

FIL大涨,灰度入局,如何参与IPFS挖矿
2021-03-23 IPFS挖矿 -

【重磅】A股上市公司斥资5.8亿布局IPFS分布式存储项目
2021-03-17 IPFS -

IPFS官方@你 | 第125期周报
2021-03-08 IPFS -

IPFS周报124期:go-ipfs 0.8.0, 远程数据固定来了!
2021-02-24 IPFS -

最新消息 | Fleek在IPFS上存储和提取文件
2021-02-24 IPFS
 矿机产品
矿机产品 算力挖矿
算力挖矿















