


 币种收益
币种收益
 矿机收益
矿机收益
 显卡收益
显卡收益
 收益计算
收益计算
 矿池信息
矿池信息
以太坊是如何运作的(三)完结篇


前言:本文主要阐述当前以太坊的具体运作原理,有助于我们理解以太坊背后的各种概念和操作,适合初学者阅读。未来ETH2.0将会发生非常大的变化,具体可以看之前的文章《ETH2.0:它会是什么?(一)》和《ETH2.0:它会是什么?(二)》。
接上一篇《以太坊是如何运作的(一)》、《以太坊是如何运作的(二)》。
合约创建
回顾一下,以太坊有两种类型账户:合约账户和外部账户。当我们说交易是“创建合约”时,我们的意思是说交易的目的是创建一个新的合约账户。
为了创建新的合约账户,我们首先使用特殊公式声明新账户地址,然后我们通过如下方式初始化新账户:
把nonce(随机数)设置为零。
如果发送人用交易发送一定量的Ether作为价值,则设置该价值为账户余额。
从发送人的余额中扣除发送给新账户的价值。
把存储设置为空。
把合约的codeHash设置为空字符串的哈希。
一旦我们初始化账户,使用跟随交易发送的init代码实际上能够创建账户(有关init代码,可参考“交易和消息”章节)。在执行这个初始化代码时会产生多样的变化。根据合约的构造函数,它可能会升级账户的存储、创建其他合约账户、进行其他消息调用等。
当执行初始化合约的代码时,它使用gas。交易不允许使用比剩余gas更多的gas。如果存在这样的情况,执行遇到gas不足的异常,然后退出。如果交易因为gas不足异常而退出,那么,状态会立刻复原到交易之前到那个点。发送人不会收到gas退款,该gas已在之前执行中用完。
但是,如果发送人用交易发送任何Ether价值,即使合约创建失败,Ether价值也会被退回。
如果初始化代码执行成功,会支付最终的成功创建合约的成本。这是存储成本,支付费用跟所创建合约代码的大小成正比,这里也没有免费午餐。如果没有足够的剩余gas来支付最终的成本,交易再次出现gas不足的异常,并中止。
如果一切都顺利,我们目前为止没有异常,则剩余的未使用的gas会退还给交易的最初发送人,由此被改变的状态也允许持续存在。
消息调用
消息调用的执行跟合约创建的执行类似,不过存在一些差异。
消息调用执行并不包括任何init代码,因为没有创建新的账户,但是,如果数据由交易发送人提供,则它可以包含输入数据。一旦执行,消息调用还有额外的组件,组件包含了输出数据,如果接下来的执行需要该数据,它会被使用。
跟合约创建一样,如果因为gas不足或交易无效(如堆栈溢出、无效跳转目标或无效指令),消息调用退出,那么,所使用的gas不会退还给最初的调用者。相反,所有剩余的未使用的gas被消耗,并且状态会复原到余额转移之前的点。
直到以太坊的最新升级之前,如果没有系统消耗你提供的所有gas,那就无法停止或恢复交易的执行。例如,假设当调用者没有被授权执行某些交易,你授权的合约抛出错误。在之前版本的以太坊,剩余的gas依然会被消耗,且没有任何gas会被退还给发送人。但在拜占庭升级中,它包括了新的“恢复”代码,允许合约停止执行并恢复状态更改,而不是消耗剩余的gas,同时还能返回交易失败的原因。如果因为还原而退出交易,则会把未使用的gas退还给发送人。
执行模式
到目前为止,我们已经了解到一个交易从开始到结束必须经历的系列步骤。现在,我们来看看交易实际上是如何在VM上执行的。
实际处理交易流程的部分协议是以太坊自己的虚拟机,也就是所谓的EVM。EVM是图灵完备的虚拟机。跟其他图灵完备的机器相比,EVM唯一的限制是它跟gas是内在绑定的。也就是说,它的计算量是受gas量内在约束的。
资料来源:CMU
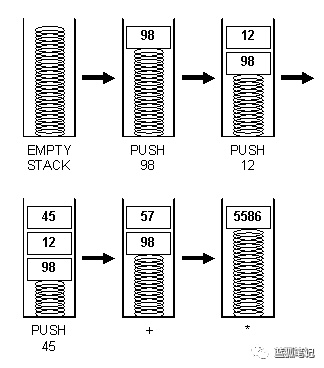
此外,EVM有基于堆栈的架构。堆栈计算机使用后进先出堆栈来保存临时值。EVM中每个堆栈项的大小是256位,堆栈最大的大小为1024。
EVM有内存,其中的item存储为字寻址字节数组。内存不稳定,意味着它不是持久的。
EVM还有存储空间。跟内存不同,存储是稳定的,同时它作为系统状态的一部分进行维持。EVM在虚拟ROM中分别存储程序代码,这些代码只能通过特别指令访问。通过这种方式,EVM跟经典的冯·诺依曼架构不同,其中的程序代码存储在内存或存储器中。
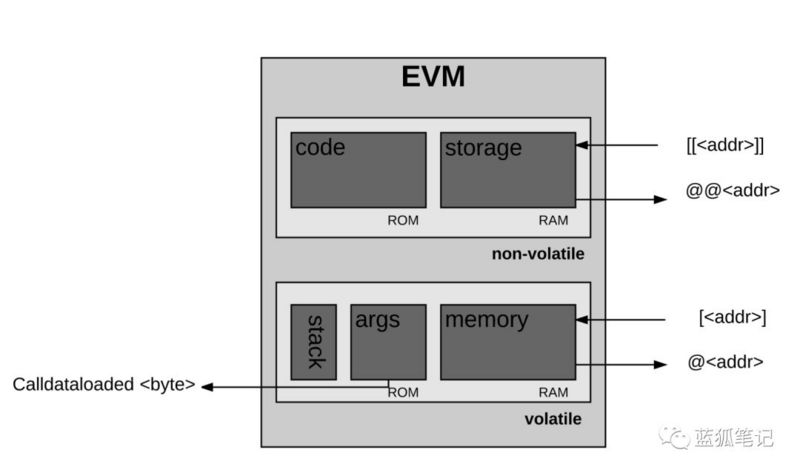
EVM也有它自己的语言:“EVM字节代码”。当一个程序员编写以太坊智能合约时,一般来说,会使用高阶语言如Solidity。之后,我们可以将其编译为EVM可以理解的EVM字节代码。
那么,现在开始执行。
在执行特定的计算之前,处理器会确保以下的信息可用且有效:
系统状态
计算用的剩余gas
拥有正在执行的代码的账户地址
发起该执行的交易发送人的地址
导致代码执行的账户地址(可能跟最初发送人不同)
产生该执行的交易的gas价格
输入该执行的数据
作为当前执行的一部分,发送价值(Wei)给此账户
要执行的机器代码
当前区块的区块头
当前消息调用或合约创建堆栈的深度
开始执行时,内存和堆栈为空,且程序计数器为零。
PC: 0 STACK: [] MEM: [], STORAGE: {}
之后,EVM递归执行交易,计算系统状态以及每个循环的机器状态。系统状态只是以太坊的全球状态。机器状态包括:
可用的gas
程序计数器
记忆内容
内存中的活跃词数
堆栈内容
从系列的最左侧部分添加或删除堆栈项。
在每个循环中,从剩余gas中减少适当的gas量,并且程序计数器递增。
在每个循环结束时,有三种可能:
1.机器达到异常状态(例如gas不足、无效指令、堆栈项不足、堆栈项因超1024而溢出、JUMP/JUMPI目的地址无效等),因此必须暂停,任何更改都将被丢弃。
2.序列继续处理进入下一个循环
3.机器达到受控停止(执行过程结束)
假设执行并没有达到异常状态,也没有达到“受控”或正常停止,则机器会生成结果状态、执行后的剩余gas、累计子状态以及结果输出。
我们了解了以太坊最复杂的部分之一。即使你不能完全明白,也没关系。除非你要从事非常深层次的工作,否则你无须理解非常细节的部分。
区块如何最终确定
最后,我们来看看包含众多交易的区块如何最终确定。
当我们说“最终确定”时,它可以意味着两种不同的东西,这取决于区块是新的还是已有的。如果它是新区块,我们指的是挖掘区块要求的过程。如果它是已有区块,那么,我们是指验证区块的过程。在任何一种情况下,有四个要求来实现区块“最终性”。
1)验证(或者,如是挖矿,确定)ommers
区块头中的每个ommer区块必须是有效的区块头,并且在当前区块的第六代内。
2)验证(或者,如是挖矿,确定)交易
区块上的使用过的gas数必须等于累积的gas,该gas被区块中列出的交易使用过。(回顾一下,当执行交易时,我们一直跟踪区块的gas计数器,它会跟踪区块中所有交易所使用的总gas)。
3)申请奖励(仅限挖矿)
受益人地址被授予5 Ether用于区块挖矿。(根据以太坊EIP-649提案,5ETH的奖励将很快会降到3ETH)。此外,对于每个ommer,当前区块的受益人将获得当前区块奖励的额外1/32。最后,ommer区块的受益人也会获得特定数量的奖励(它根据特殊公式来计算,这里不详述。)
4)验证(或者,如果挖矿,计算有效的)状态和nonce
确保所有的交易和结果状态改变得到应用,然后,在所有区块奖励已经被应用到最终的交易结果状态后,定义新区块作为状态。通过针对存储在区块头的状态trie来检查该最终状态,以此进行验证。
PoW挖矿
“区块”章节部分简要介绍了区块难度的概念。赋予区块难度意义的算法叫PoW。以太坊的PoW算法称为“Ethash”(曾经叫做Dagger-Hashimoto)。
算法正式定义如下:
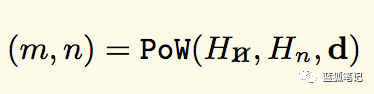
其中的m是mixHash,n是nonce(随机数),Hn是新区块头(不包括nonce和mixHash组件,它们必须计算出来),Hn是区块头的nonce,并且d是DAG,它是大的数据集。
在“区块”章节部分,我们提过区块头存在的各种item。其中两个组件叫做mixHash和nonce。你可能还记得:
mixHash是一个哈希值,当它跟nonce结合使用时,证明该区块已经执行足够的计算。
nonce是一个哈希值,当它跟mixHash结合时,证明该区块已经执行足够的计算。
PoW功能用于评估以上两个item。
使用PoW函数来计算mixHash和nonce有些复杂,我们可以用单独文章来深入研究。但在更高的层面上,它是这样工作的:
“为每个区块计算“种子”。该种子对于每个“epoch”都是不同的,其中每个epoch都是30,000区块长度。对于第一个epoch,种子是一系列32字节的零的哈希。对于后续的epoch,它是之前种子哈希的哈希。这样,使用该种子,节点可以计算伪随机的“缓存”。”
这个缓存非常有用,因为这让“轻节点”的概念变得可行。轻节点的目的是可以让特定的节点有能力验证交易,但与此同时无需存储整个区块链的数据集。轻节点可以验证交易的有效性,它只是基于这个缓存,因为缓存可以重新生成它要验证的特定区块。
使用缓存,节点能够生成DAG“数据集”,其中数据集中每个item依赖于来自缓存的一小部分伪随机选择的item。为了成为矿工,你必须生成这个全数据集;所有全数据客户端和矿工存储这个数据集,并且这个数据集随着时间线性增长。
矿工可以获取随机数据集切片,并把它们用数学函数进行一起哈希,变成“mixHash”。矿工将重复生成mixHash直到输出低于所需的目标nonce。当输出满足需求,nonce被认定为有效,同时区块被添加到链上。
挖矿是一种安全机制
总体来说,PoW的目的是用加密安全的方式证明一定量的计算已经消耗在生成某个输出上(即,nonce随机数)。这是因为没有更好的方法来找到一个随机数,这个随机数低于所需的阀值,而不是枚举所有的可能性。重复应用哈希函数的输出具有均匀分布,所以,我们可以肯定,平均来说,找到这样一个随机数所需的时间取决于困难阀值。难度越高,找到nonce的时间就越长。通过这种方式,PoW算法为难度概念赋予了意义,它用于确保区块链的安全。
区块链的安全是什么意思?很简单:我们希望的创建一个人人都可信任的区块链。我们之前也提过,如果多于一条链存在,用户会失去信任,因为他们不能合理地确定哪条链是“有效”的区块链。为了让一群用户接受存储在区块链上的底层状态,我们需要单一规范的区块链,而这条区块链人人都相信它。
这就是PoW算法的作用:它确保特定区块链将一直保持规范,让它很难被攻击者攻击,攻击者很难创建新的区块来重写交易的历史(也就是,抹除交易或创建分叉交易)或维持分叉。为了让他们的区块首先被验证,攻击者需要持续地在网络中比其他人更快地算出随机数,也因此,网络才会相信他们的链是最长的链(基于GHOST协议的原则)。这将是不可能的,除非攻击者拥有超过一半以上的算力,也就是所谓的51%攻击场景。
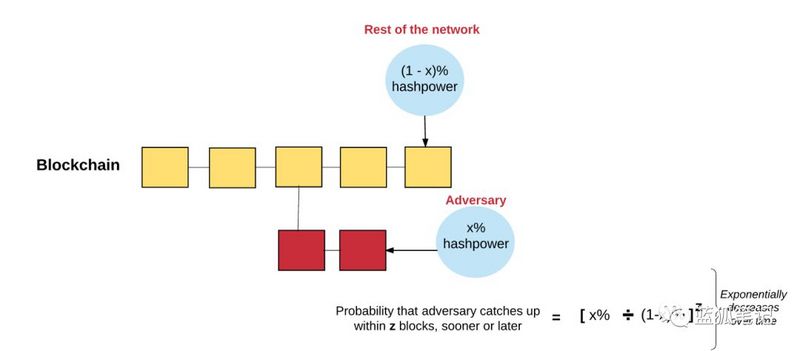
挖矿作为财富分配机制
除了提供安全的区块链之外,PoW也为那些耗费算力提供安全的人提供财富分配的方式。回顾一下,矿工从挖矿中获得奖励,包括:
获胜区块会获得5 Ether 的静态区块奖励(很快会变成3个 Ether)
区块中交易的gas成本
包含ommers作为区块一部分的额外奖励
PoW算法机制是安全和财富分配的方法,为了确保它是长期可持续的,以太坊努力地灌输这两个属性:
让尽可能多的人可以访问它。换句话说,人们不需要特制的或不常见的硬件来运行算法。它的目的在于让财富分配模型尽可能开放,以让任何人都可以通过提供一定的算力来获得Ether的奖励。
减少任何单一节点获取不成比例收益的可能性。任何节点如果可以获取不成比例的收益,这也意味着该节点会拥有决定规范区块链的巨大影响力。这是很麻烦的,因为它降低了网络的安全性。
在比特币区块链网络中,与上述两个属性相关的一个问题是PoW算法是SHA256哈希函数。这种类型函数的弱点是使用特定的硬件会更有效率,众所周知的是ASICs。
为了减轻这个问题,以太坊选择了的PoW算法是Ethhash,它的算法让序列记忆很难。这意味着以太坊的算法设计让计算随机数需要很多内存和带宽。对于计算机来说,大内存需求让它很难使用内存进行平行计算来同时发现多个随机数,同时,更高的带宽要求让它很难同时发现多个随机数,即使是超高速的计算机也是如此。这就降低了中心化的风险,并为验证节点们创建了一个更加公平的竞争环境。
有一点需要注意的是,以太坊正在从一个PoW共识机制转变为所谓的“PoS”证明。这个问题很丰富,也许在未来可以单独文章探讨。
结语
这篇文章有很多内容需要消化。如果需要阅读几次才能理解,也是可以的,我希望以上的阐述对你有所帮助。
声明:此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述。本网站所提供的信息,只供参考之用。
- 相关阅读
-

Bitcoin的算力暴跌:矿工面临利润骤降的困境
2025-01-12 -

欢迎加入VolcMiner火山矿机交流群
2024-12-06 -

自由开放透明的矿机革命 - 新一代DOGE矿机VOLCMINER D1发布
2024-10-17 -

Coin Metrics:2024年Q3比特币矿业报告
2024-10-10 -

Aleo 主网上线天王变“天亡”?矿工直呼被坑惨
2024-09-22
 矿机产品
矿机产品 算力挖矿
算力挖矿















